Publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2026
- ACL 2026
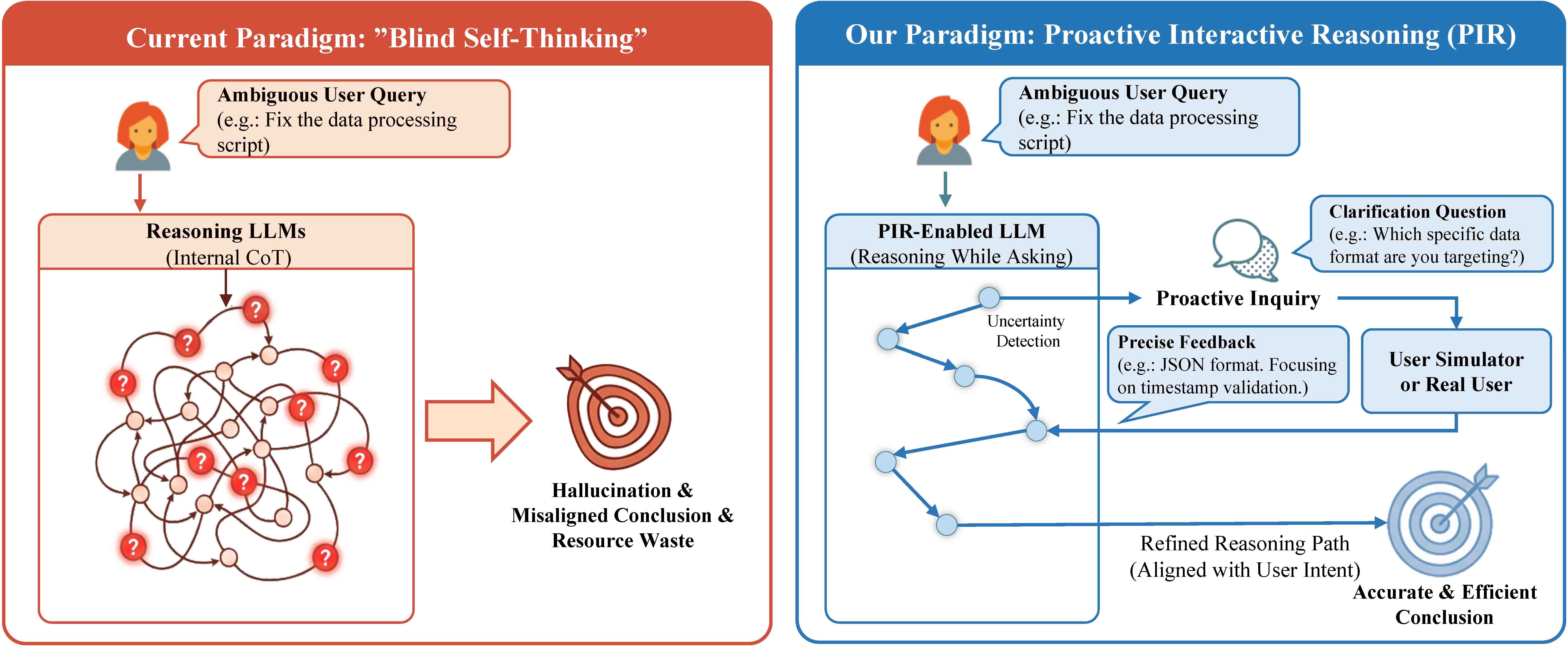 Reasoning While Asking: Transforming Reasoning Large Language Models from Passive Solvers to Proactive InquirersXin Chen, Feng Jiang, Yiqian Zhang, and 5 more authorsThe 64th Annual Meeting of the Association for Computational Linguistics, Apr 2026
Reasoning While Asking: Transforming Reasoning Large Language Models from Passive Solvers to Proactive InquirersXin Chen, Feng Jiang, Yiqian Zhang, and 5 more authorsThe 64th Annual Meeting of the Association for Computational Linguistics, Apr 2026Reasoning-oriented Large Language Models (LLMs) have achieved remarkable progress with Chain-of-Thought (CoT) prompting, yet they remain fundamentally limited by a \emphblind self-thinking paradigm: performing extensive internal reasoning even when critical information is missing or ambiguous. We propose Proactive Interactive Reasoning (PIR), a new reasoning paradigm that transforms LLMs from passive solvers into proactive inquirers that interleave reasoning with clarification. Unlike existing search- or tool-based frameworks that primarily address knowledge uncertainty by querying external environments, PIR targets premise- and intent-level uncertainty through direct interaction with the user. PIR is implemented via two core components: (1) an uncertainty-aware supervised fine-tuning procedure that equips models with interactive reasoning capability, and (2) a user-simulator-based policy optimization framework driven by a composite reward that aligns model behavior with user intent. Extensive experiments on mathematical reasoning, code generation, and document editing demonstrate that PIR consistently outperforms strong baselines, achieving up to 32.70% higher accuracy, 22.90% higher pass rate, and 41.36 BLEU improvement, while reducing nearly half of the reasoning computation and unnecessary interaction turns. Further reliability evaluations on factual knowledge, question answering, and missing-premise scenarios confirm the strong generalization and robustness of PIR.
@article{chen2026reasoning, title = {Reasoning While Asking: Transforming Reasoning Large Language Models from Passive Solvers to Proactive Inquirers}, author = {Chen, Xin and Jiang, Feng and Zhang, Yiqian and Chen, Hardy and Yan, Shuo and Xie, Wenya and Yang, Min and Huang, Shujian}, journal = {The 64th Annual Meeting of the Association for Computational Linguistics}, year = {2026}, month = apr, } - ICLR 2026
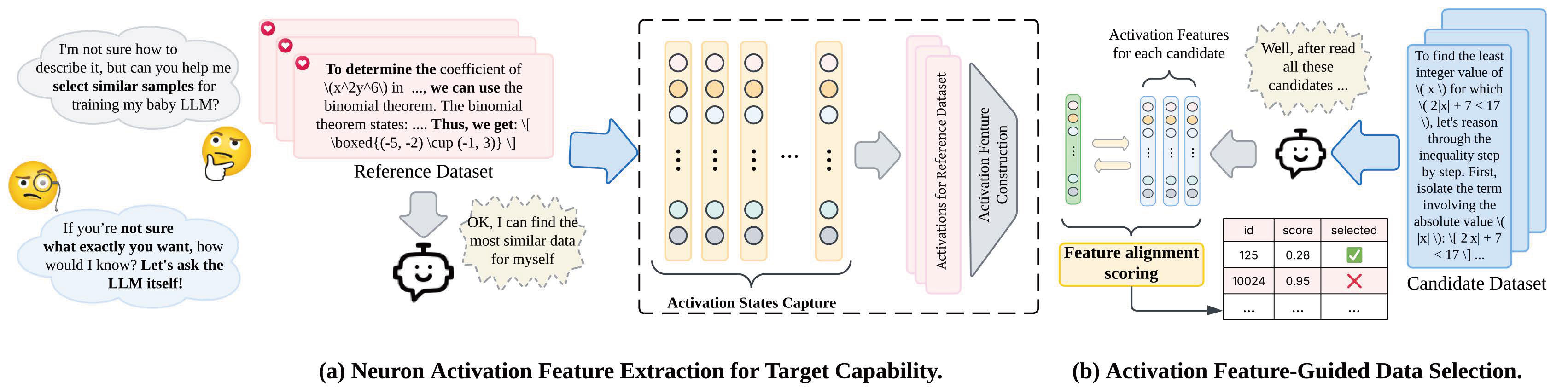 Neuron-Aware Data Selection in Instruction Tuning for Large Language ModelsXin Chen, Junchao Wu, Shu Yang, and 6 more authorsIn International Conference on Learning Representations (ICLR), 2026
Neuron-Aware Data Selection in Instruction Tuning for Large Language ModelsXin Chen, Junchao Wu, Shu Yang, and 6 more authorsIn International Conference on Learning Representations (ICLR), 2026Instruction Tuning (IT) has been proven to be an effective approach to unlock the powerful capabilities of large language models (LLMs). Recent studies indicate that excessive IT data can degrade LLMs performance, while carefully selecting a small subset of high-quality IT data can significantly enhance their capabilities. Therefore, identifying the most efficient subset data from the IT dataset to effectively develop either specific or general abilities in LLMs has become a critical challenge. To address this, we propose a novel and efficient framework called NAIT. NAIT evaluates the impact of IT data on LLMs performance by analyzing the similarity of neuron activation patterns between the IT dataset and the target domain capability. Specifically, NAIT captures neuron activation patterns from in-domain datasets of target domain capabilities to construct reusable and transferable neuron activation features. It then evaluates and selects optimal samples based on the similarity between candidate samples and the expected activation features of the target capabilities. Experimental results show that training on the 10% Alpaca-GPT4 IT data subset selected by NAIT consistently outperforms methods that rely on external advanced models or uncertainty-based features across various tasks. Our findings also reveal the transferability of neuron activation features across different capabilities of LLMs. In particular, IT data with more logical reasoning and programmatic features possesses strong general transferability, enabling models to develop stronger capabilities across multiple tasks, while a stable core subset of data is sufficient to consistently activate fundamental model capabilities and universally improve performance across diverse tasks.
@inproceedings{chen2026neuron, title = {Neuron-Aware Data Selection in Instruction Tuning for Large Language Models}, author = {Chen, Xin and Wu, Junchao and Yang, Shu and Zhan, Runzhe and Wu, Zeyu and Yang, Min and Huang, Shujian and Chao, Lidia S. and Wong, Derek F.}, booktitle = {International Conference on Learning Representations (ICLR)}, year = {2026}, } - TACL 2026
 Understanding Aha Moments: From External Observations to Internal MechanismsShu Yang, Junchao Wu, Xin Chen, and 4 more authorsTransactions of the Association for Computational Linguistics (TACL), 2026
Understanding Aha Moments: From External Observations to Internal MechanismsShu Yang, Junchao Wu, Xin Chen, and 4 more authorsTransactions of the Association for Computational Linguistics (TACL), 2026Large Reasoning Models (LRMs), capable of reasoning through complex problems, have become crucial for tasks like programming, mathematics, and commonsense reasoning. However, a key challenge lies in understanding how these models acquire reasoning capabilities and exhibit "aha moments" when they reorganize their methods to allocate more thinking time to problems. In this work, we systematically study "aha moments" in LRMs, from linguistic patterns, description of uncertainty, "Reasoning Collapse" to analysis in latent space. We demonstrate that the "aha moment" is externally manifested in a more frequent use of anthropomorphic tones for self-reflection and an adaptive adjustment of uncertainty based on problem difficulty. This process helps the model complete reasoning without succumbing to "Reasoning Collapse". Internally, it corresponds to a separation between anthropomorphic characteristics and pure reasoning, with an increased anthropomorphic tone for more difficult problems. Furthermore, we find that the "aha moment" helps models solve complex problems by altering their perception of problem difficulty. As the layer of the model increases, simpler problems tend to be perceived as more complex, while more difficult problems appear simpler.
@article{yang2025aha, title = {Understanding Aha Moments: From External Observations to Internal Mechanisms}, author = {Yang, Shu and Wu, Junchao and Chen, Xin and Xiao, Yunze and Yang, Xinyi and Wong, Derek F. and Wang, Di}, journal = {Transactions of the Association for Computational Linguistics (TACL)}, year = {2026}, }
2025
- TACL 2025
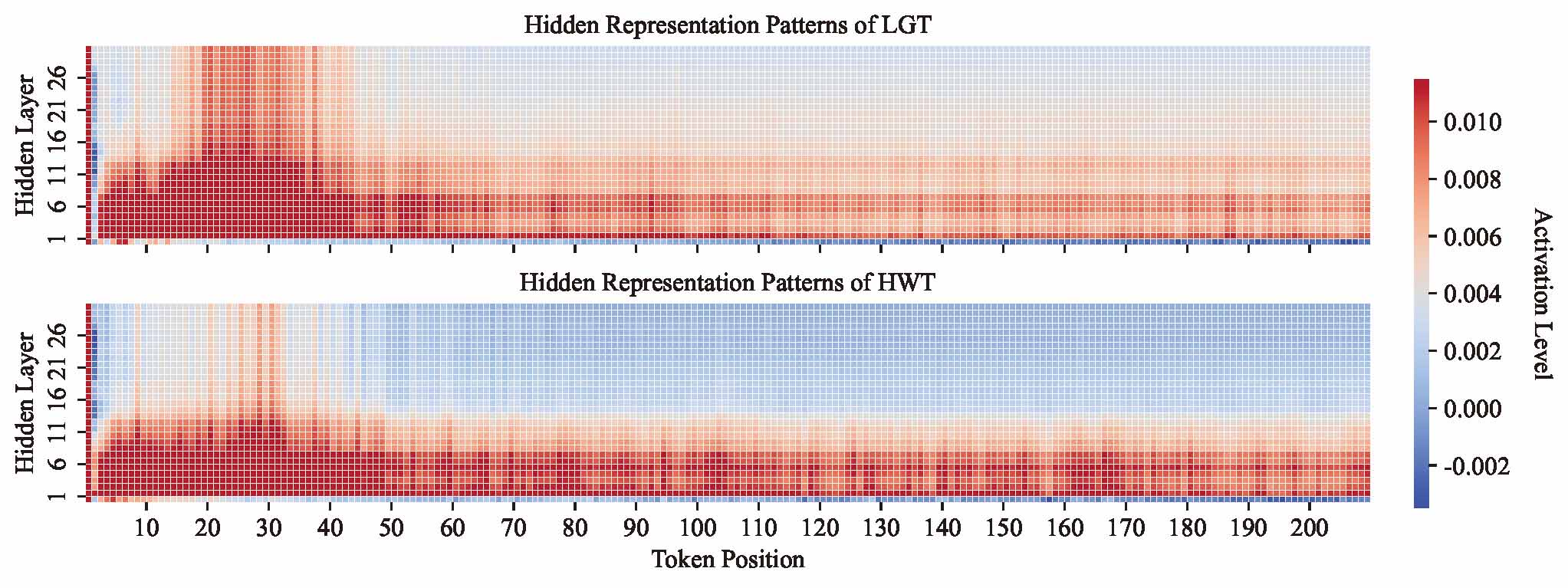 RepreGuard: Detecting LLM-Generated Text by Revealing Hidden Representation PatternsXin Chen, Junchao Wu, Shu Yang, and 7 more authorsTransactions of the Association for Computational Linguistics (TACL), 2025
RepreGuard: Detecting LLM-Generated Text by Revealing Hidden Representation PatternsXin Chen, Junchao Wu, Shu Yang, and 7 more authorsTransactions of the Association for Computational Linguistics (TACL), 2025Detecting content generated by large language models (LLMs) is crucial for preventing misuse and building trustworthy AI systems. Although existing detection methods perform well, their robustness in out-of-distribution (OOD) scenarios is still lacking. In this paper, we hypothesize that, compared to features used by existing detection methods, the internal representations of LLMs contain more comprehensive and raw features that can more effectively capture and distinguish the statistical pattern differences between LLM-generated texts (LGT) and human-written texts (HWT). We validated this hypothesis across different LLMs and observed significant differences in neural activation patterns when processing these two types of texts. Based on this, we propose RepreGuard, an efficient statistics-based detection method. Specifically, we first employ a surrogate model to collect representation of LGT and HWT, and extract the distinct activation feature that can better identify LGT. We can classify the text by calculating the projection score of the text representations along this feature direction and comparing with a precomputed threshold. Experimental results show that RepreGuard outperforms all baselines with average 94.92% AUROC on both in-distribution and OOD scenarios, while also demonstrating robust resilience to various text sizes and mainstream attacks.
@article{chen2025repreguard, title = {RepreGuard: Detecting LLM-Generated Text by Revealing Hidden Representation Patterns}, author = {Chen, Xin and Wu, Junchao and Yang, Shu and Zhan, Runzhe and Wu, Zeyu and Luo, Ziyang and Wang, Di and Yang, Min and Chao, Lidia S. and Wong, Derek F.}, journal = {Transactions of the Association for Computational Linguistics (TACL)}, year = {2025}, }
2024
- arXiv
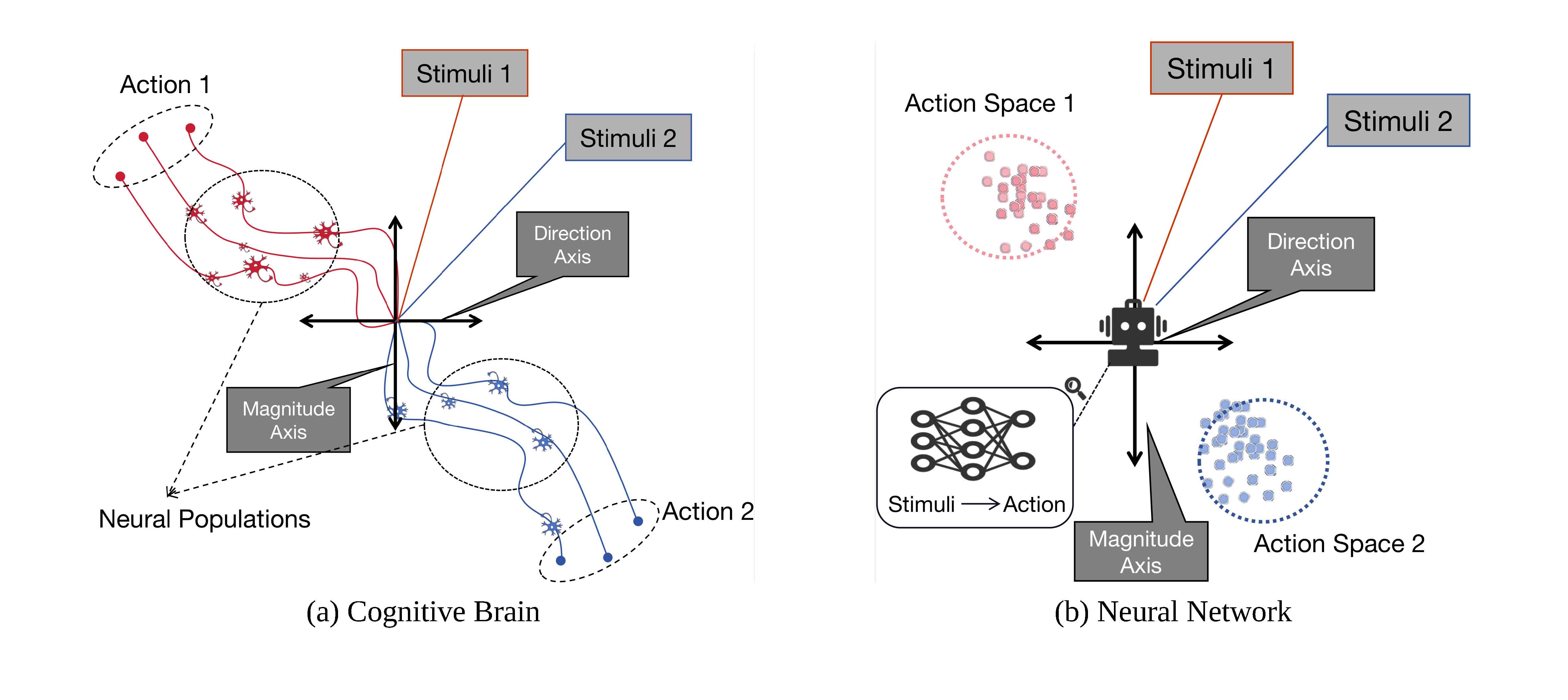 Understanding Reasoning in Chain-of-Thought from the Hopfieldian ViewLijie Hu, Liang Liu, Shu Yang, and 6 more authorsarXiv preprint, 2024
Understanding Reasoning in Chain-of-Thought from the Hopfieldian ViewLijie Hu, Liang Liu, Shu Yang, and 6 more authorsarXiv preprint, 2024Chain-of-Thought (CoT) holds a significant place in augmenting the reasoning performance for large language models (LLMs). While some studies focus on improving CoT accuracy through methods like retrieval enhancement, yet a rigorous explanation for why CoT achieves such success remains unclear. In this paper, we analyze CoT methods under two different settings by asking the following questions: (1) For zero-shot CoT, why does prompting the model with "let’s think step by step" significantly impact its outputs? (2) For few-shot CoT, why does providing examples before questioning the model could substantially improve its reasoning ability? To answer these questions, we conduct a top-down explainable analysis from the Hopfieldian view and propose a Read-and-Control approach for controlling the accuracy of CoT. Through extensive experiments on seven datasets for three different tasks, we demonstrate that our framework can decipher the inner workings of CoT, provide reasoning error localization, and control to come up with the correct reasoning path.
@article{hu2024hopfieldian, title = {Understanding Reasoning in Chain-of-Thought from the Hopfieldian View}, author = {Hu, Lijie and Liu, Liang and Yang, Shu and Chen, Xin and Xiao, Hongru and Li, Mengdi and Zhou, Pan and Ali, Muhammad Asif and Wang, Di}, journal = {arXiv preprint}, year = {2024}, }
2021
- ICEIT
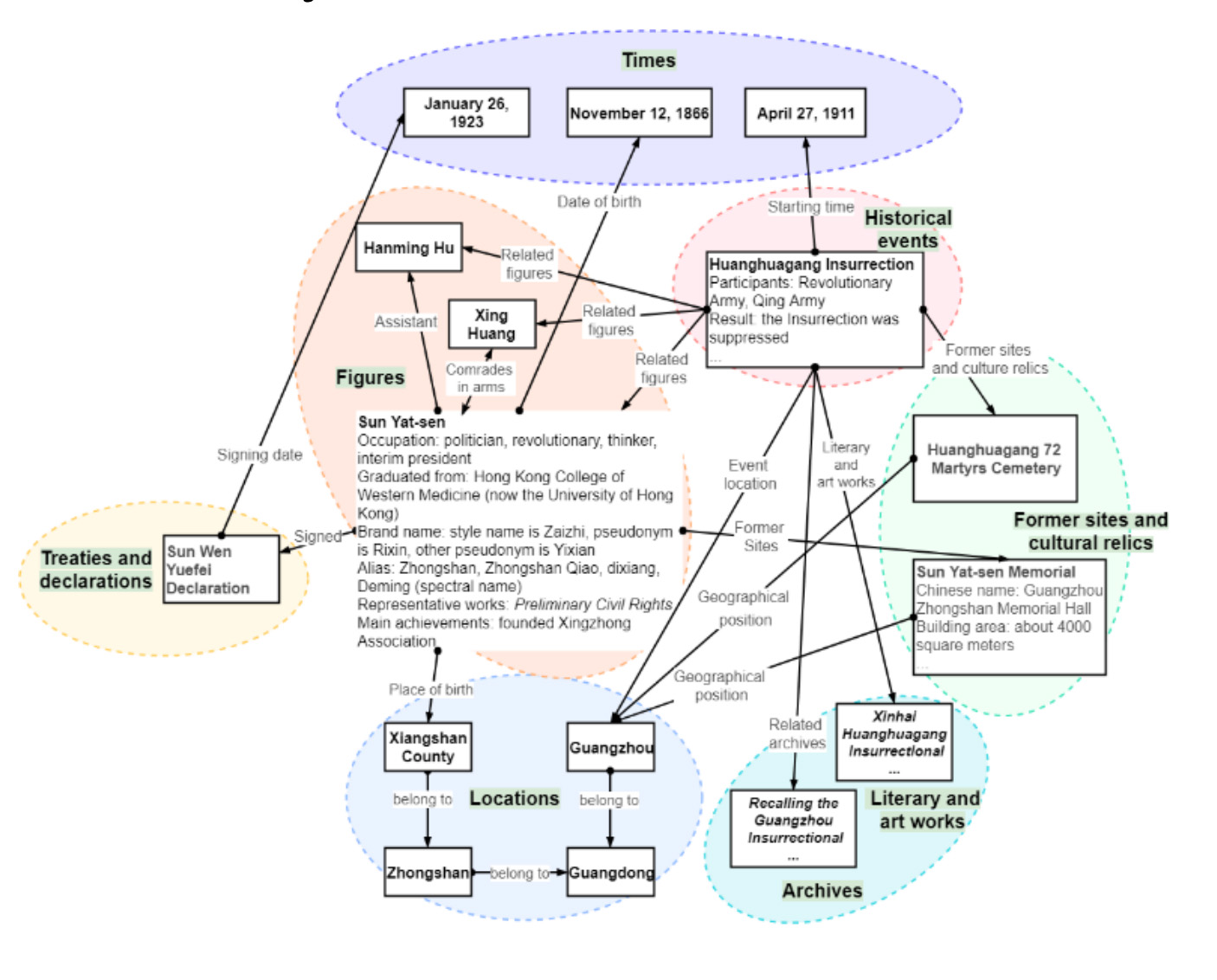 "The Canton Canon" Digital Library Based on Knowledge Graph—Taking the Revolutionary Archives of Canton in the Republic of China as an ExampleJunchao Wu, Ying Jiang, Xin Chen, and 3 more authorsIn 2021 IEEE 10th International Conference on Educational and Information Technology (ICEIT), 2021
"The Canton Canon" Digital Library Based on Knowledge Graph—Taking the Revolutionary Archives of Canton in the Republic of China as an ExampleJunchao Wu, Ying Jiang, Xin Chen, and 3 more authorsIn 2021 IEEE 10th International Conference on Educational and Information Technology (ICEIT), 2021Best Presentation Award
@inproceedings{wu2021canton, title = {"The Canton Canon" Digital Library Based on Knowledge Graph---Taking the Revolutionary Archives of Canton in the Republic of China as an Example}, author = {Wu, Junchao and Jiang, Ying and Chen, Xin and Guo, Lingyu and Wei, Xiaotong and Yang, Xiaoyan}, booktitle = {2021 IEEE 10th International Conference on Educational and Information Technology (ICEIT)}, pages = {171--179}, year = {2021}, publisher = {IEEE}, doi = {10.1109/ICEIT51700.2021.9375538}, }